
seleniumでキャプチャ自動保存にチャレンジしたかったが、ひとつづつURLを入力していたら自動化の意味がないのでテキストファイルから読み込んで複数繰り返し処理をしてほしかった。
簡単なコードしか知らないので基本的な方法のみです。処理は遅いので今後もっと早くできるライブラリにも挑戦したいね。
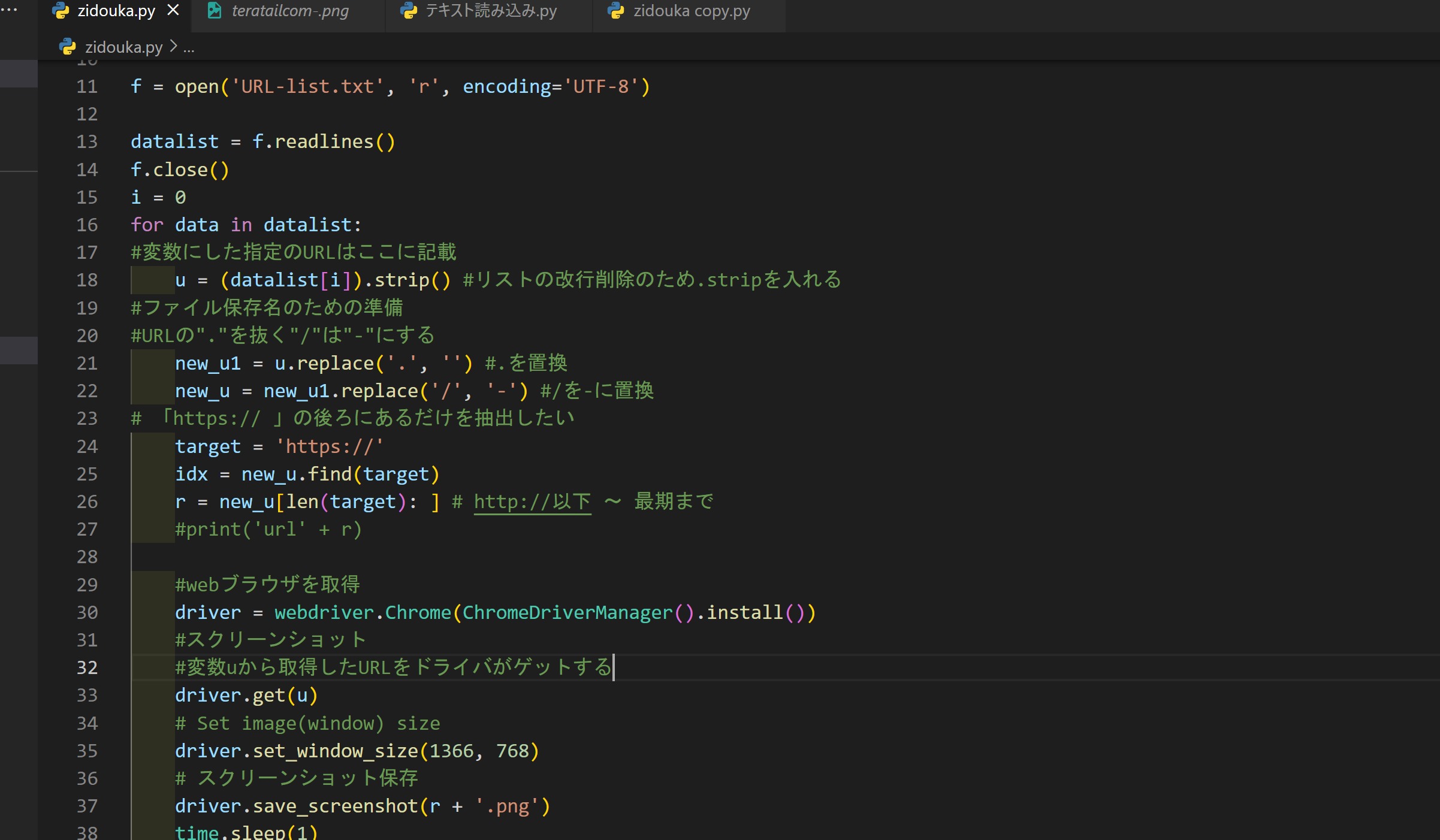
#キャプチャ自動保存 ファイル名をURLにする
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager #WEBドライバ自動更新
#import chromedriver_binary #WEBドライバ自動更新いれたのでいらない
import time
f = open('URL-list.txt', 'r', encoding='UTF-8')
datalist = f.readlines()
f.close()
i = 0
for data in datalist:
#変数にした指定のURLはここに記載
u = (datalist[i]).strip() #リストの改行削除のため.stripを入れる
#ファイル保存名のための準備
#URLの"."を抜く"/"は"-"にする
new_u1 = u.replace('.', '') #.を置換
new_u = new_u1.replace('/', '-') #/を-に置換
# 「https:// 」の後ろにあるだけを抽出したい
target = 'https://'
idx = new_u.find(target)
r = new_u[len(target): ] # http://以下 ~ 最期まで
#print('url' + r)
#webブラウザを取得
driver = webdriver.Chrome(ChromeDriverManager().install())
#スクリーンショット
#変数uから取得したURLをドライバがゲットする
driver.get(u)
# Set image(window) size
driver.set_window_size(1366, 768)
# スクリーンショット保存
driver.save_screenshot(r + '.png')
time.sleep(1)
# ドライバを閉じる
driver.quit()
i = i + 1
つまづいた点
リスト化した際、最後のひとつしか保存されなかった
【解決策】リストの改行のせいでスクリーンショットしなかった。
改行削除を変数宣言時に.stripを入れる
u = (datalist[i]).strip() ドライバーのバージョンちがいエラー
【解決策】自動更新設定を入れる
from webdriver_manager.chrome import ChromeDriverManager #WEBドライバ自動更新 #webブラウザを取得
driver = webdriver.Chrome(ChromeDriverManager().install())参考にしたサイト様

【Selenium】ChromeDriver自動更新で楽する方法【Python】 - ゆうきのせかい
Selenium ManagerでPython Selenium ChromeDriver手動更新の面倒から解放されよう。Selenium4.5以下の場合はwebdriver-managerライブラリ。
yuki.world
突然エラーが出るようになった
ログ取るの忘れていたがアクセス違反といったエラーが突然出るようになった。
【原因】URLメモリストに不要なテキストが入っていた(おばか~
コメント